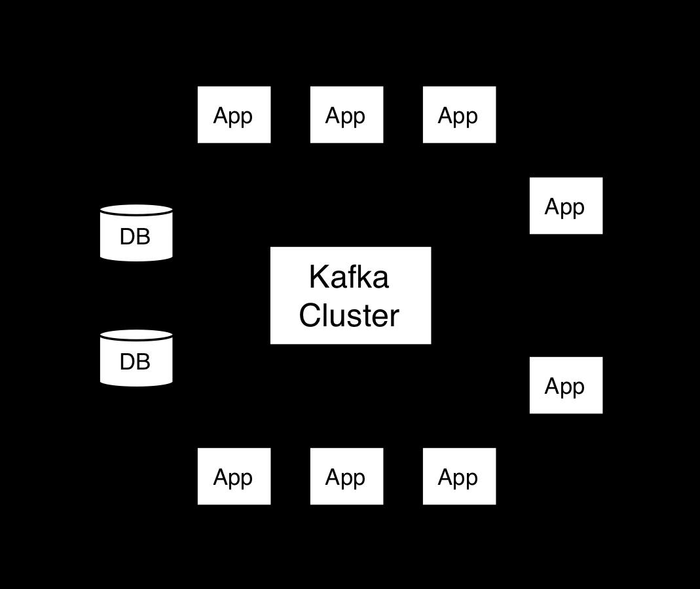
[BigDataHadoop:Hadoop&kafka.V07] [BigDataHadoop.kafka][|章节四|Hadoop生态圈技术栈|kafka|源码剖析|Kafka源码剖析之Producer消费者流程|]
一、自动提交
### --- 自动提交
~~~ 最简单的提交方式是让悄费者自动提交偏移量。
~~~ 如果enable.auto.commit被设为 true,消费者会自动把从 poll() 方法接收到的最大偏移量提交上去。
~~~ 提交时间间隔由 auto.commit.interval.ms 控制,默认值是 5s。
~~~ 与消费者里的其他东西 一样,自动提交也是在轮询(poll() )里进行的。
~~~ 消费者每次在进行轮询时会检查是否该提交偏移量了,
~~~ 如果是,那 么就会提交从上一次轮询返回的偏移量。
~~~ 不过,这种简便的方式也会带来一些问题,
### --- 来看一下下面的例子:
~~~ 假设我们仍然使用默认的 5s提交时间间隔,在最近一次提交之后的 3s发生了再均衡,
~~~ 再 均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。
~~~ 这个时候偏移量已经落后 了 3s,所以在这 3s 内到达的消息会被重复处理。
~~~ 可以通过修改提交时间间隔来更频繁地提交偏移量,减小可能出现重复消息的时间窗,
~~~ 不过这种情况是无也完全避免的
二、手动提交
### --- 同步提交
~~~ 取消自动提交,把 auto.commit.offset 设为 false,让应用程序决定何时提交 偏 移量。
~~~ 使用commitSync() 提交偏移量最简单也最可靠。
~~~ 这个 API会提交由 poll() 方法返回 的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常
while (true) {
// 消息拉取
ConsumerRecords
for (ConsumerRecord
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(),record.key(), record.value());
}
// 处理完成单次消息以后,提交当前的offset,如果提交失败就抛出异常
consumer.commitSync();
}
### --- 异步提交
~~~ 同步提交有一个不足之处,
~~~ 在 broker对提交请求作出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。
~~~ 我们可以通过降低提交频率来提升吞吐量,但如果发生了再均衡, 会增加重复消息的数量。
~~~ 这个时候可以使用异步提交 API。我们只管发送提交请求,无需等待 broker的响应。
while (true) {
// 消息拉取
ConsumerRecords
for (ConsumerRecord
System.out.printf("offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
}
// 异步提交
consumer.commitAsync((offsets, exception) -> {
exception.printStackTrace();
System.out.println(offsets.size());
});
}
===============================END===============================
来自为知笔记(Wiz)







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有